完美国际私服是中国第一开服网[ssswm.haowm.com]
时间:2023-02-19 18:56:32
人气:
编辑:佚名
Facebook 算法的背后是人。

编者按:你登陆社交网站,以为新闻就是你订阅的内容,其实也包括平台想让你看到的,猜测你可能喜欢什么。 平台会猜测用户的心思,用户往往沦为实验品。 这篇文章由 SLATE 编译,揭示了 Facebook News Feed 背后的技术原理。 科技公司努力了解您。
每次你打开 Facebook,世界上最强大、最有争议和最容易被误解的算法之一就会启动。它会收集关于你的一切的状态更新:你朋友发布的每周状态、你关注的每个人、你加入的每个群组以及你的每条消息喜欢。 对于 Facebook 用户,每周平均有 1,500 次状态更新。 如果你有数百个朋友,这个数字可以高达 10,000 或更多。 通过对这些数据的细致观察,工程师们不断优化推荐算法,让Facebook的news feed能够展示出你真正感兴趣的内容。因为大多数人不会每天完整地阅读timeline,而是只看前几百个.
没有人能准确猜出 Facebook 的算法是如何生成的,更不可能有内部人士告诉你这一点。 这种自动化算法对人们的社交互动有重大影响,它决定了我们每天看到的内容,考虑到世界五分之一的人口——近 10 亿活跃的 Facebook 用户每天都在新闻源中阅读新闻。 病毒传播的算法机制彻底颠覆了传统媒体,将新兴创业公司BuzzFeed和Vox的市值推上了高位,而百年历史的报纸也陆续被带入坟墓。 社交游戏公司Zynga和团购网站LivingSocial,在与Facebook的短短一两年内就实现了数十亿美元的估值,投资者赚得盆满钵满。 Facebook的动态新闻甚至可以控制我们的情绪,它给我们推送真正优质有趣的新闻,过滤掉的只是情绪化的表达。
然而,尽管其功能强大,但它的动态消息一直不能令人满意,其内容随意、不可预测,有时甚至完全不雅。 经常有无关紧要的事情、谣言、琐事、气话或无趣的消息。 Facebook 内部的人很清楚这一点。 在过去的几个月里,这家社交网络巨头已经开始在用户小范围内测试重新设计的 feed 算法,你猜怎么着?
用户普遍报告说“有时”新的新闻提要会触动他们的兴奋点。 Facebook对此表示欣慰,并强调会继续改进。
“有时”意味着你离完全成功还有很长的路要走。
近年来,Facebook 和其他硅谷巨头已经习惯于使用机器学习软件为我们做出选择。 硅谷巨星埃隆·马斯克和著名科学家史蒂芬·霍金都曾提出警惕人工智能的观点,而“算法”这个词本身就是为了大大提高效率而诞生的。 对于普通人来说,“算法”是一个“面目全非”的计算机名词。 它神秘而充满魔力,Facebook等科技巨头使用的算法更是让人好奇。
最近,我访问了 Facebook 总部,与新闻源算法团队共度时光,了解了这一机制背后的故事。 他们如何扭转臭名昭著的新闻提要算法,他们为什么这样做,他们是如何做到的,以及它是如何工作的。 此外,我们还可以了解到很多算法的局限性,数据有时会说谎。 Facebook 专门聘请了一个外包团队进行人工反馈,以获得更准确的结果。
算法
据我所知,Facebook 的算法有一点缺陷,而不是系统问题。 以目前的技术水平,算法不可能做到科幻小说般洞悉人性。 Facebook 算法的背后是人。 工程师决定数据过滤、处理和输出。 如果算法出了问题,当然是设计算法的工程师负责。 算法的一步步演进,也是无数工程师看了无数资料,开了无数会议,反复测试的最终结果。 然而,Facebook算法的不断进步还是让人疑惑,他们是怎么做到的?

当我到达 Facebook 总部时,迎接我的是一位 37 岁的男孩,他笑容和蔼,精力充沛,渴望表达自己。 他就是“Feed News”算法的工程总监Tom Alison,他管理着设计算法的工程师。
艾莉森带我穿过 Facebook 办公室的迷宫,穿过一个小厨房,进入一个小会议室。 艾莉森向我保证,她会解释 Facebook 算法背后的基本原理,甚至对像我这样的外行也是如此。 到了那里,我想去洗手间,就问他怎么去。 他抱歉地对我说:“让我带你去吧。” 一开始我以为他怕我迷路,结果从洗手间出来,发现他站在门口等我。 我不禁想到,他是被上司要求不要让我一个人在办公室里走来走去。

脸书总部
同样,Facebook 对他们的商业信息守口如瓶,Alison 无法告诉我有关 News Feed 算法的实际代码。 但是,他能够大致告诉我它是如何工作的,以及为什么它会不断变化。 工程师平时都喜欢站在白板前讲解,他也不例外。
刚开始学计算机的时候,第一个接触到的算法肯定是关于排序的。 他飞快地在白板上写下了这些数字:4、1、3、2、5。
然后,他写下了一个简单的任务:设计一个算法,将数组从小到大排序。 “人类可以如此轻松地做到这一点,只需动动手指,”他告诉我。
但是,对于计算机,您应该给出具体且明确的方法。 这就是算法的用武之地:算法是计算机用来解决问题的一系列步骤。 艾莉森告诉我,这个算法叫做“冒泡排序”,它的具体方法如下:
冒泡排序的优点是简单易懂。 缺点也很明显。 如果你的数据太大,计算量会很大,速度也会变慢。 对于 Facebook 的数十亿用户来说,当然不能使用这种算法。 Facebook的算法要求你在打开App的一瞬间准确投放所有动态消息,速度要求极其严格。 但这只是算法中的子算法。 最重要的是以正确的方式对所有新闻提要进行排序,最重要的出现在顶部。 这就是Facebook news feed排序团队的工作,就是把用户关心的所有信息按照用户的相关性进行排序。
这是一项非常艰巨的任务。 因为你的朋友在 Facebook 上发的消息,还有你关注的名人发的消息,“与你有关”的东西是很难量化的。 为此,Alison 解释说,Facebook 使用了一组不同的算法,称为预测算法。 (Facebook的news feed算法,Google的搜索引擎算法,Netflix的推荐算法都是分布式的复杂算法,包括很多小算法)
让我们猜猜下一场篮球比赛,公牛队对湖人队,谁会赢? 艾莉森说。 “公牛,”我不假思索地说。 艾莉森笑了,但随后点头同意。 如果把我的大脑比作一台电脑,我只是输入他的问题,输出牛的答案,我大脑的直觉反应就是算法。 (人脑的算法比现在的电脑复杂很多,但是稳定性也差很多)
“当你没有压力时,这种基于直觉的猜测非常准确,”艾莉森说。
“但是如果刚才的预测跟货币挂钩,每次上百万,一天上百个预测,那我们就需要一个系统的方法,你可以看看历史数据,每支球队的输赢记录,是不是伤病,谁正手火热。也许你还考虑环境因素,谁是主队?客队是背靠背比赛还是有休息时间?你的算法可能会考虑所有这些因素。如果你的算法足够完美,你不仅可以预测结果,甚至可以猜出比分。”
Facebook 的 News Feed 算法也是如此。 (新闻是Facebook最大的摇钱树,日均收入2000万美元。)我问艾莉森Facebook算法的机器学习语言考虑了多少条件,他回答“数百”。

亚当·莫塞里(站立)

整个信息流算法设计团队
它不只是根据您过去的喜好习惯来预测您是否会喜欢它。 它还可以预测您点击展开、评论、分享甚至标记为垃圾邮件的可能性有多大。 这决定了相关性得分,决定了它是否会出现在您的新闻提要列表中以及出现在何处。 因此,每次您在 Facebook 动态消息中打开第一条消息时,它都会从数百条消息中脱颖而出完美国际代码动态,最能激发您点赞、评论、分享和改变心情的消息。
喜欢
然而,无论你多么仔细地构建算法,总有很多数据是你不知道的:教练的比赛计划、德里克罗斯(公牛队球星)的膝伤,甚至篮球的气压。 从微观层面看,比赛并不是纯粹的比拼。 这是一个人参与的游戏,“人”的复杂性远非算法所能预测。
这套预测算法还面临着认识论方面的其他挑战。 相关分数预测公牛队将赢得比赛。 显然,这个结果是可以量化的:赢或输,猜对或猜错。 Facebook 试图用类似的想法解决这个问题,记录你与这些新闻源互动的频率。 而这些互动恰好是 Facebook 的收入来源:点赞、点击、分享、评论、新闻的病毒式传播、链接每一个用户以及精准的广告。
但是这些交流对于真实用户来说是非常粗略和不准确的。 他们喜欢,但并不一定代表他们真的很喜欢这个新闻,故事讲到一半就关掉也不一定代表他们不喜欢。 如何优化这种情况?

“喜欢”
2013年底,Facebook已经是当时最火的公司。 用户数量超过10亿,估值达到1000亿美元以上。 当时,他们已经花费数年时间不断优化移动端的应用体验。 在国际上,它们的受欢迎程度已经超过了谷歌搜索和谷歌地图。
Facebook 不再只是朋友之间的社交工具。 事实上,它也是21世纪的全球新闻源:一个为每个用户量身定做、即时更新的新闻、娱乐、交友动态聚合网站。
在公司中,他们对动态消息收入的增长感到震惊。 但在用户数量猛增的同时,Facebook 员工并不确定用户的满意度如何。 人们比以往任何时候都更喜欢 Facebook,但他们讨厌什么?
要弄清楚这一点,我们必须回到 2006 年。与今天复杂的侧边栏和群组相比,当时的 Facebook 还很原始。 与其竞争对手 Myspace 一样,News Feed 只是朋友之间状态更新的集合。
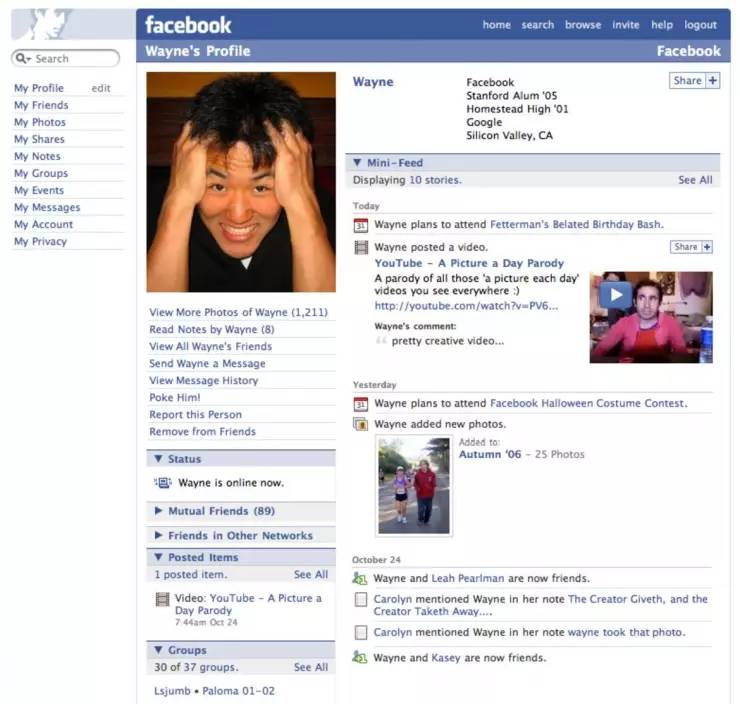
2006年的Facebook页面
甚至,您可能无法看到朋友的更新。 为了防止信息过多给用户造成太大的压力,Facebook采用了一种简单粗暴的算法,过滤掉一些它认为用户不感兴趣的信息。当时并没有办法衡量用户是否感兴趣在信息方面,类似的功能还需要三年时间。 工程师依靠直觉来确定消息是否存在。 开始的标准是消息发布了多长时间以及您的朋友提到它的次数。 一段时间后,工程师们决定停止这种简单粗暴的方式,以用户在消息上停留的总时长作为消息重要度的依据。 但这样的机制很难区分哪些消息取悦用户,哪些消息冒犯用户,哪些无聊,哪些纯粹是谣言。 从本质上讲,工程师们仍在冒险。
“点赞”功能并不是一种新的交流方式。 Facebook推出点赞功能的初衷是为了了解用户对新闻的喜好。 用户可能没有意识到这是一个非常精巧的设计。 如果用户清楚地知道“点赞”是为了方便 Facebook 的偏好记录,那么这个过程就会显得非常繁琐。 Facebook 的“动态”算法是世界上第一个在用户感觉不到的情况下了解用户习惯和偏好的算法,它影响着我们所有人。
没有丝毫防御,该算法会在不知不觉中发现实时热点并使它们传播开来。 以前的热点都是一个人链式传播,现在一个人点赞后,他所有的朋友都能看到这条消息,传播效率堪比滚雪球。 这种效果不仅Facebook员工看到,广告商、出版商、造谣者,就连普通用户也见识到了它的强大——只要点个赞,就可以把消息传播给所有的朋友、Followers甚至陌生人. 不少人开始绞尽脑汁思考如何打造“引爆点”。 它甚至催生了一个新职业——专门教授人类地位的社交网络顾问。 他们精通研究文字、发布消息的时间和照片对病毒式传播的影响。 “求点赞”成了常态,连发状态的她们都忘记了初衷。 很多人头发的状态已经变得同质化:庸俗、虚伪、自怜,只为获得更多的“赞”。 “大拇指”成为社交网络的中心。
人类反馈
这样一来,网站的交互性得到了很大的提升,但这应该是News Feed所追求的吗? 这个问题一直困扰着Facebook资深人士、动态算法工程师Chris Cox。 “观察用户的点赞、点击、分享、评论等行为,是为了更好地了解用户的心理。” 考克斯在电子邮件中告诉我。 (他是 Facebook 的首席产品官。)“但我们知道这不是一个完美的解决方案。例如,当你看到一个悲伤的新闻故事时,你肯定不喜欢它,但这并不意味着你不感动。。几年过去了,我们需要了解比点赞和点击更详细的用户行为。”
一个算法可以尽可能计算出最优解,但如果不是最优解,就得靠人来判断了。 Cox 等人为新闻推送机制设定的最终目标是将人们真正相关的所有新闻进行排序,隐藏所有不相关的新闻。 他们知道这意味着要牺牲一些短期的广告收入和用户体验。 Facebook目前持有大量现金,CEO扎克伯格有一个长期目标,这给了他们宝贵的试错机会。 但如何抓住机会,还是要看他们自己了。
长期以来,媒体机构依靠主观判断来确定受众感兴趣的内容。这种判断影响编辑讲故事的方法、价值取向、新闻价值判断和主题选择。 但这种主观判断是考克斯和其他 Facebook 同事试图避免的。 他们和Facebook想要的效果是:用户在自己的动态中看到自己感兴趣的内容,而不是Facebook推送的内容。 “完美的解决方案是让用户可以选择他们想看的内容,但这显然不切实际,”考克斯告诉我。 所以下一个最好的解决方案是使用算法来猜测用户喜欢什么,然后付钱给一群人看看它是如何工作的。 事实上,这个外包团队已经达到了千人之多。 他们以前在诺克斯维尔的办公室工作,但现在他们在自己家里工作。

32 岁的 newsfeed 产品负责人 Adam Mosseri 与 Alison 处于同一水平,但前者更注重战略,而后者更注重技术细节。 他发现了问题,Alison 解决了它。 他负责从哲学层面思考新闻提要问题。
News Feed 的人性化一面始于 Mosseri 的前任主管 Will Cathcart。 Cathcart的工作是从收集更详细的信息开始的,不仅是用户点击了什么,还有用户在每个页面停留的时间,不仅是用户点赞的内容和倾向,还有他在查看之前是否点赞,我看完会喜欢的。 Facebook 倾向于认为您不喜欢您在阅读之前喜欢的新闻。
自2013年上任以来,莫塞里又有了大动作。 2014 年夏天,他创建了“新闻提要质量评估小组”。 您自己的 Facebook 动态消息时间表,以及向 Facebook 工程师反馈的详细信息和满意度。 (他们其实是Facebook的一个秘密外包团队。)Mosseri和工程师不止于此,他们还会问体验者为什么喜欢,为什么不喜欢,喜欢的标准对自己,以及喜欢的人趋势 。 “事实上,他们几乎每天都写调查报告完美国际代码动态,”评估小组主任格雷格马拉告诉我。
“问题是,我们可能错过了什么?” 莫塞里说。 “真相的哪一方面是我们的盲点?” 讨论交流。 如果你不注意这种情况,算法会误认为你对这些消息不感兴趣,因为你既没有点赞也没有评论。 那这些消息和普通消息有什么区别呢?”
Mosseri 任命了产品经理 Max Eulenstein 和用户体验研究员 Lauren Scissors 来管理审查团队的日常运作,并回答问题。 例如,Eulenstein 要求小组成员观看一个故事,并测试他们在喜欢或不喜欢这个新闻时在页面上停留了多长时间。 人们普遍认为,您在页面上停留的时间越长,您对它就越感兴趣,即使您不“喜欢”它也是如此。 “但没那么简单,不是‘喜欢5秒,不喜欢2秒’”,Eulenstein向我解释道,“每个用户的阅读速度也大不相同,这个时间值应该和平均阅读时间一样用户综合考虑。” 这个问题的研究结果体现在6月份的一次算法改进中,Facebook将尝试对用户停留时间最长的新闻进行排名。
经过数月的工作,莫塞里和他的团队终于建立了一个可信的评估团队,一个国际团队,根据全球 Facebook 用户数量分配团队成员的国籍,并允许他们在家工作。 . 2015 年底,Facebook 解散了其前诺克斯维尔办事处,并将其测试团队扩展到海外。 Mosseri 的直觉是正确的:新闻源算法推荐中有一个工程师自己无法发现的盲点。 这就需要另一种数据支撑——人肉反馈。

评估团队对新闻提要算法的成熟起到了至关重要的作用。 摆脱对“大数据”的迷信后,团队迅速壮大。 相反,它是一个具有完整反馈和平衡机制的系统。 每一次算法的改变,都必须经过不同类型、不同国籍用户的反馈,并通过多维度的标准检验来保证准确性。
这个包括排序工程师、产品经理和数据分析师在内的小团队的主要任务是平衡算法的准确性。 Sami Tas 是软件工程师之一,他的工作是将新闻点餐团队编写的对象(即伪代码)翻译成计算机可以理解的语言。 今天下午,当他从我身边经过时,我盯着他看,因为一个看似微不足道的问题而烦恼。 这是一个非常微不足道的问题,但 Facebook 的员工却非常吝啬。
5% 的用户
大多数时候,人们看到一条他们不感兴趣的消息并直接跳过。 但是有些消息让他们很烦,他们点击下拉菜单找到“隐藏”按钮。 Facebook 的算法将“隐藏”视为强烈的不满信号,并尽量减少类似消息的出现。
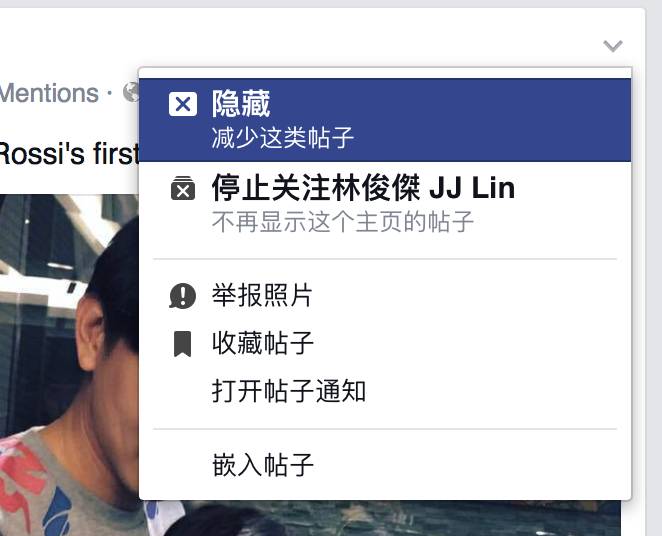
“隐藏”功能隐藏在下拉栏的二级菜单中
显然,每个用户的习惯都不一样,有趣的是,Facebook的数据分析师发现,有5%的用户使用“隐藏”功能,占总数的85%。 他们更深入地了解到,这一小群人隐藏了他们看到的几乎所有新闻——甚至是他们喜欢或评论的新闻。 对于这些“隐藏”的强迫症患者来说,显然,“隐藏”并不代表他们不喜欢新闻,他们想要表达的是“已读”标记,就像Gmail中的“存档”一样。
然而,他们的行为会使他们排序所依据的数据产生偏差。 对于如此复杂的情况,算法无法区分这种行为。 它只会傻傻地认为喜欢就是满足,藏起来就是强烈的不满。 因此,对于这种“隐性”强迫症患者,工程师们决定对其进行专项优化。 Tas专门写了代码来识别这群人,降低他们“隐藏”的负权重。
这似乎是个小问题。 但这个算法对 Facebook 来说太重要了,这么小的改动在使用之前应该经过严格的测试。 它从线下测试开始,在 Facebook 内部小组中进行小测试,然后向一小部分用户推广,最后推广到全面使用。 在每一步,数据分析师都必须收集有关用户与网站的互动、广告收入以及对加载速度的影响的信息。 如果任何项目大幅波动,就会发出警报,并自动通知工程师。
即便如此,Facebook 也不能确定会产生负面的长期后果。 为了防止意外,还有一个“保留群”,即少数用户会在数月内保持不变。
有一种普遍的误解,认为不仅有一套动态消息排序算法。 事实上,这不是一套数百个小算法。 由于一共有很多测试组,也就是“保留组”,所以世界上同时运行着多个版本的排序算法。 我猜想,一些“‘隐性’强迫症患者”可以愉快地滚动浏览动态消息,但仍有一些用户仍然被不准确的算法所困扰。

质评团队的出线,让动态新闻算法团队的数据更加立体,这是大数据无法给出的。 到目前为止,Tas 和分拣团队的其他成员对机器算法的盲点有了深刻的了解。 不过,Facebook上还有另外一个群体,对这个算法的成熟也起到了关键作用,那就是普通用户,包括你我。
在过去的六个月里,Facebook 一直在对普通用户进行随机调查,在左右设置动态消息两栏,让普通用户选择更感兴趣的栏目。 这是一个全民参与的“动态新闻评测团”。 但更重要的是,在过去两年中,Facebook 一直在为用户提供更多定制他们的 News Feed 的权力。
您不仅可以“取消关注”某人,还可以将您的好朋友放在优先列表中并阻止某些类型的消息。 当然,这些功能粗心的用户很难找到,也不会增加轻度用户的上手成本——它隐藏在右上角的灰色小箭头中。 大多数用户甚至永远不会发现这些功能。 当你打开导航和帮助页面时,Facebook 会详细解释这些功能。
你了解你自己吗
这些转变部分是防御性的。 近年来,Facebook在社交网络领域的霸主地位一再受到威胁,就像MySpace的地位受到Facebook的挑战一样。 新兴的初创公司完全避免了数据驱动模型。 以 Instagram 为例,他们直接将你关注的每个人的状态信息按反时间顺序列出。 Facebook 不得不收购 Instagram 来维持老大哥的地位。 Sanpchat以其独特的阅后即逝模式正在侵蚀Facebook的青年市场。
近年来,Facebook 并不是唯一一家以数据为驱动来优化其推荐算法的公司。 Netflix的最佳电影推荐也有大量的用户数据,将用户分成无数个子类别,按类别进行推荐。 为了平衡亚马逊的自动化 A/B 测试,CEO 贝佐斯一直在设立一个单独的反馈邮箱供用户提交评论。 将数据的处理完全交给机器学习还为时过早,但机器学习的时代正在加速到来。 Facebook 的负责人莫塞里不喜欢在会议中使用流行的“数据驱动”,他说“数据辅助”。

Facebook News Feed Ranking Team 相信他们的辛勤工作会得到回报。 “如果我们继续根据反馈改进动态消息,我们将越来越接近人们想要的东西,”与反馈团队合作的用户体验分析师 Scissors 说。
这里有一个潜在的缺点:给用户控制权,但他们真的知道自己想要什么吗? 还是数据驱动的 Facebook 比我们更了解自己? 是否有可能使新闻提要比用户自己想要的更具吸引力?
Mosseri 告诉我他并不过分担心这个。 他解释说,到目前为止的这些数据意味着应该做更多的研究,应该给用户更多的选择,这可以增加用户的参与度和在网站上的停留时间,这两者在短期内似乎都是最重要的目标。
动态消息推送算法的改进是一个非常长期的过程。 如果它每次都正好击中你的痛点,那只是一个愉快的巧合。 在运行新闻源的十年中,数据从未像现在这样好。 算法的改进是一个否定对否定的过程。 今天写的代码,明天可能会被无情删掉。 日复一日,工程师们在位于门洛帕克的 Facebook 总部报告研究经验,召开会议,进行一系列测试,并一次又一次地调整算法。

智能硬件第一媒体 长按二维码关注